
None of these dinky test datasets for Dr Evil. I wanted to see MVS running in TK4- do some real work…with one million records! So I created an empty 3350 to test load a AWSTAPE containing one million 163 byte records. The records are 164 bytes on tape because of the added line end character, but 163 bytes loaded. The extra line end character is not needed on MVS and was ignored at load time. It was added because editors on Linux (my OS) would choke trying to load a million byte line, which the editor would assume without it. MS-Windows requires 2 bytes for their line end.
These are fake but real looking records with…
- Valid looking account numbers (meaning they check digit)
- First Name
- Middle Name
- Last Name
- A couple dates
- An amount field
- Address
- City
- State
- Zip
Sample below
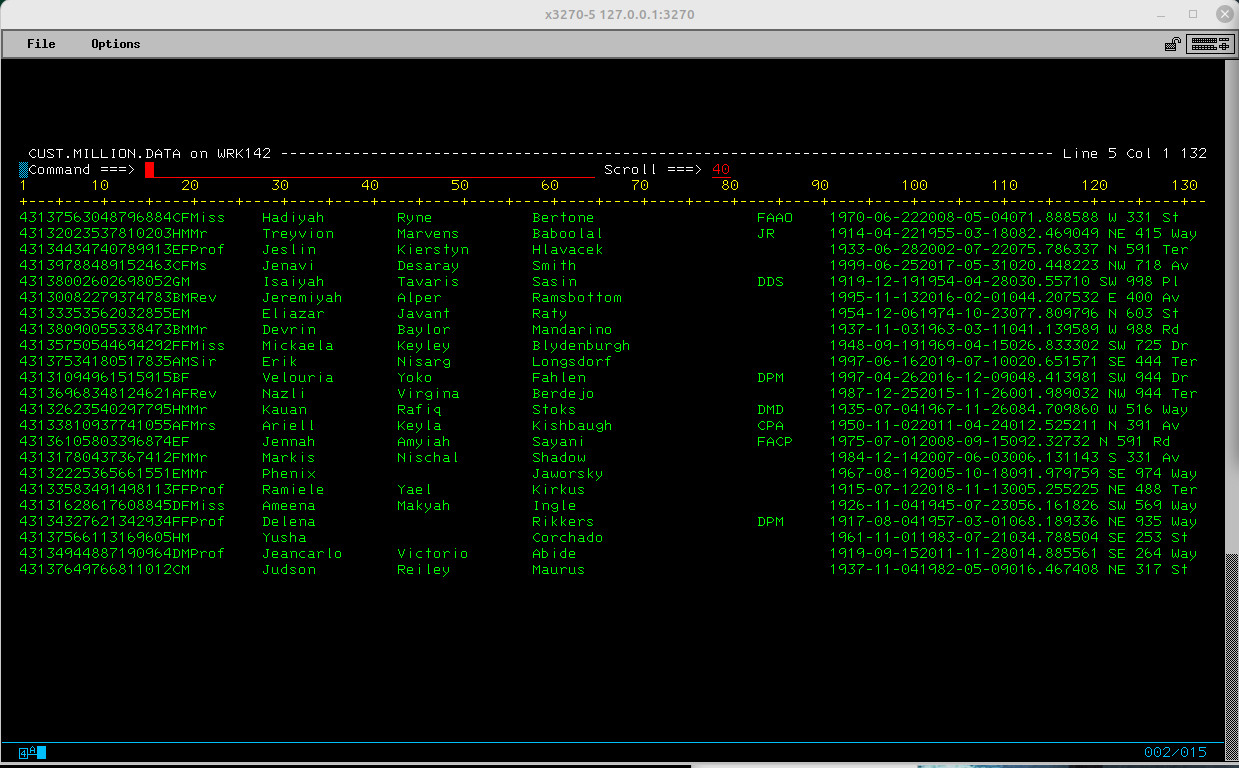
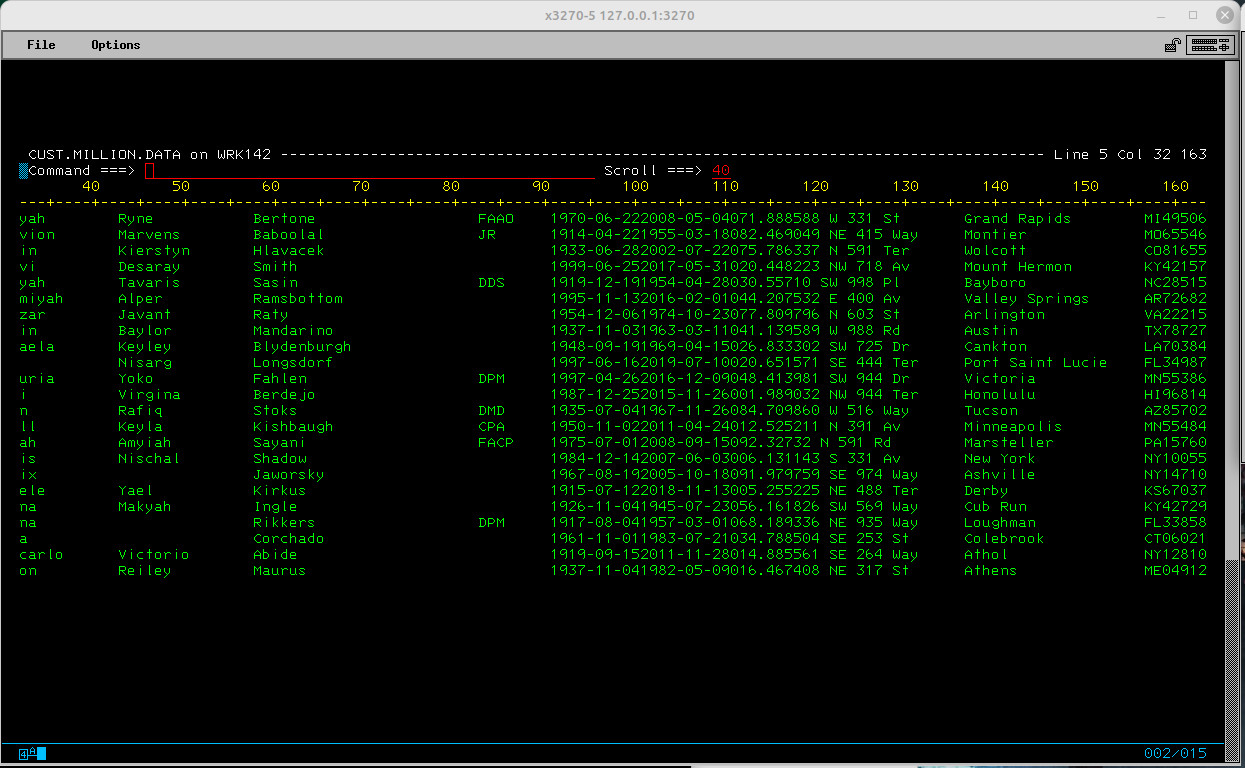
Not surprisingly it’s a 164MB Linux file. The AWSTAPE created from that file is 164.1MB. I tested with IEBGENER and a COBOL program and each took around a whole 3 seconds to load the data. The CPU time for the COBOL program was slightly less, but not enough to matter. However the COBOL program saved one million bytes because I could control the output and didn’t have to output the line ending character. We were very aware of those extra bytes…back in the day.
I later learned IEBGENER can change the LRECL on output.
For whatever reason this was something I was very curious about. To see how efficiently MVS under Hercules, handled a large amount of records. At least a large amount of records from the era of MVS 3.8j, before Big data was a thing. Pretty well IMHO.